本文共 3335 字,大约阅读时间需要 11 分钟。
指令乱序和内存障碍(barrier)
什么是指令乱序?
指令乱序分为执行指令乱序(cpu)和编译器指令乱序。
执行指令乱序(cpu)
要了解cpu执行指令乱序,我们要先了解cpu的流水线pipeline.
cpu处理指令时,将指令的处理过程分为取指、译码、[访存]、执行、[回写]等几个阶段。
取指:顾名思义,就是到内存中(I-cache)取要执行的指令
译码:cpu识别这个指令是做什么的,比如识别出操作码[op]、操作数等
访存:cpu锁定内存的地址
执行:执行指令操作,比如ADD、sub或将内存中的数据加载到cpu寄存器中
回写:cpu将寄存器中的数据写回内存中。
如果cpu只有”一套”pipeline,那么后一条指令必须等待前一条指令执行完毕,才能执行,即使前一条指令是费时很长的IO指令(访问外设、内存等),这种方式极大的浪费了cpu资源。
为了提高CPU效率,cpu内部会有很多个“取指、译码、[访存]、执行、[回写]”器件。
所有没有显式依赖的指令可以同时取指、译码、执行而不必等待。这样大大提高了cpu的效率,提升了cpu单个指令周期内的执行指令的数目。
比如原本指令的执行顺序如下:
ldr r0, [r1]
mov r2, $3
sub r0, r2
str r0, [r1]
如果指令是按序执行的,则执行顺序如下:
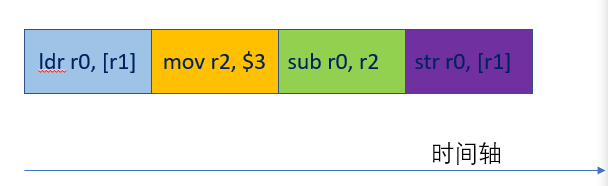
图1:指令按序执行
但在现代高级的,支持多指令并发的CPU中,实际的指令执行序列可能为下面这样的:

图2:指令乱序执行
图2中第二条指令与第一条指令并发执行了,而原本是在第一条指令执行后才执行的,这就是”乱序”了。
一般地,cpu不会刻意去乱序指令,它总是按序取走指令,但是一些指令在执行时需要依赖其他指令的执行结果,那这条指令就对其他指令有依赖,它需要等待依赖指令的结果才能继续执行。
所以,对于有依赖关系的指令,cpu还是会保证指令的执行顺序的。当然,如果依赖的指令相隔很远,cpu是无法甄别出的,此时不会保证这种依赖指令的执行顺序。
比如:
a++;
b=f(a);
c--;
这里,第二条指令显式依赖第一条指令的结果, cpu执行时就不会破坏第一第二条指令的执行顺序。而第三条指令和第一第二条指令没有关系,所以,第三条指令可能在第一第二条指令执行时也开始执行。
上述内容描述了指令乱序的由来,以及cpu指令乱序带来的效率提升。所谓有利必有弊,下面我们来说说指令乱序带来的弊:
我们以一个例子来说明:
*addr=5;
val=*data;
上述代码运行在单核单线程系统中,由于这两条语句没有显式的依赖关系,cpu将并发执行。
但是考虑下,如果这段代码是硬件操作呢?硬件要求先发送要访问的设备上内存或寄存器的地址,然后再读走数据。那么这两段代码就有依赖关系,这种依赖关系就是隐式依赖。
显然,cpu无法处理隐士依赖,乱序执行将会得到不期望的结果。
再举一个单核多线程的例子:

线程1给data和ready赋值,两者没有显式依赖关系,cpu乱序执行时,有可能ready被赋予新值后,再执行给data赋值。如果,ready复制后发生了中断,导致ready值更新了,而data值未能更新,再中断返回时调度了线程2,有可能导致线程2调用do_something()而出现非预期的执行path。
再来看一个多核多线程例子:

当线程1执行时,由于这两条语句并没有显式的依赖关系,cpu将并发执行(str)。如果此时ready在cache中命中,而data cache missing,这将导致ready先于data更新了内存中的数据。那么 core1中的线程2会执行do_something(),由于data数据并没有更新,故会有问题。
上述例子中,除开cache命中的原因外,再多核多线程系统中,还有其他原因会导致data、ready乱序。
我们来理解下这个多核多线程下的数据同步过程:
core0下对data写新数据,首先会更新到core0的cache中,由于cache中标记了这个cache line(data所在的cache line)是共享的,cache会向core1 cache发送同步指令,让core1 cache更新其cache中data的数据。cache中的data新数据则在后面择机写入内存中。
在有些cpu中存在多个cache列(alpha),如果data和ready分别在core0的不同cache列,即使我们在core0 thread1中增加内存barrier,仍然存在乱序问题。如下图:

core0线程1增加了wmb,保证了data先于ready更新数据,更新cache会使cache发出同步消息,让core1也更新自己的cache。由于他们分属不同的cache列,wmb()会使得‘data’ cache更新消息早于‘ready’ cache更新消息早发出。但是如果此时,在core1上data所在的cache列busy,而ready cache列idle,这也会导致在core1 cache中,ready的值更新过了,而data仍为旧值,这会导致core1线程2会调用do_something(), 从而导致问题。
为了解决上述问题,core1上线程的指令也需要保证不乱序,如下:

上图中,core0线程1中增加了写内存障碍wmb(),这保证了data先于ready更新内存数据,且保证cache中data更新消息早于ready更新消息发向core1.
同样的core1上线程2使用了rmb()保证了data, ready的cache内容按收到的更新消息的次序更新。
说完cpu指令执行乱序后,我们来说说编译器乱序。
首先,既然已经有了cpu乱序执行以提高cpu运行效率,那为什么还要有编译器乱序?
cpu的乱序程度依赖于cpu并发处理指令的能力,只能乱序附近比较小块的的指令。而编译器则可以从更大程度(范围)来调整指令的次序,从而来提高性能。
举个例子:

在编译器优化之前,ready的赋值是最后一条语句,编译器发现这个值和其他语句没有显式依赖,则启用编译器优化后,有可能成为第一条语句。
至此,我们说完了cpu乱序和编译器乱序。
那么,如何防止这两种乱序呢?
Linux kernel提供了内存barrier函数,来阻止cpu乱序和编译器乱序。如下:

注:MP为多处理器,UP为单处理器。
总之,我们编程时,要考虑这几个问题:
- 单线程下,cpu乱序执行是否会有问题。如果有问题,指令是否是显式依赖,如果是,则不用处理,cpu能处理这种依赖,如果是隐式依赖,则需要加memory barrier。
- 多线程下,是否有乱序问题。如果有乱序,那么乱序是否有问题。如果有问题,则需加memory barrier处理(cache 同步)
最后,我们来看看这么些个内存barrier函数的实现(ARMv6指令集)。
arch/arm/include/asm/barrier.h



ARM中内存barrier有3种,DMB, DSB, ISB
DMB: data memory barrier
DSB: data synchronize barrier
ISB: instruction synchronize barrier
这3种barrier在ARMv6中通过协处理器p15的c7寄存器来配置。

上图中,<C5, 4 >Flush Prefetch Buffer对应ISB,<C10, 4> Data Synchronization Barrier对应DSB,
<C10, 5> Data Memory Barrier对应DMB。
DMB和DSB的区别:
DMB和DSB都保证barrier前的内存访问指令完成后才能执行barrier后的内存访问指令,且DMB在DMB后的其他和内存无关的指令和barrier指令可以乱序执行;而DSB则任何在barrier后的指令都不能在barrier完成之前执行。
ISB则会使cpu在barrier完成后丢弃pipeline中的指令,重新从memory/Cache取指令。
转载地址:http://jtlci.baihongyu.com/